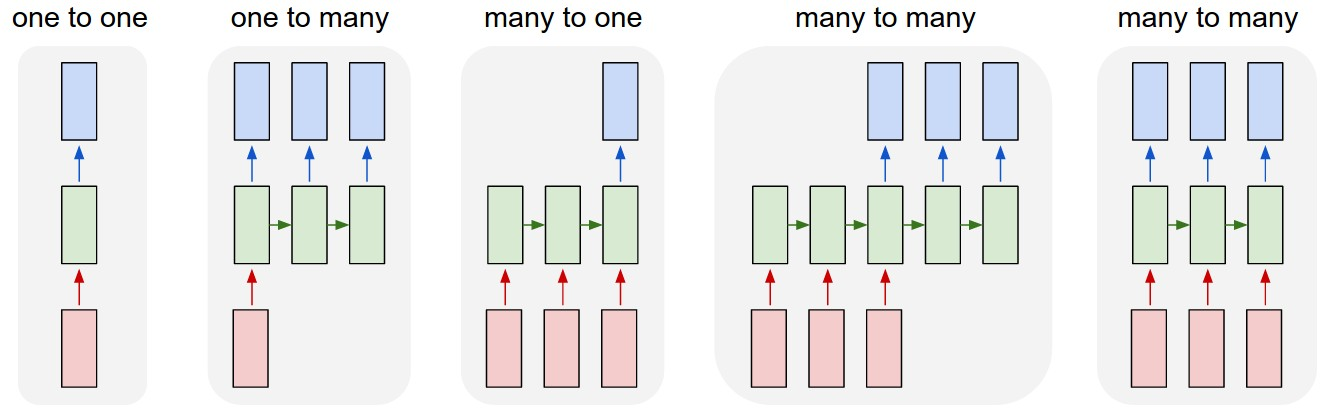
Generally a difference for machine learners can be made by the nature of input and output.
source
One to one
Typically an application would be to classify the main motive of a picture (e.g. cat or dog) or the emotional category that is displayed in an audio recording. Key is, that the input is represented by a single vector of values of fixed length.
One to many
Many to one
Sequence to sequence
Many to many
This is a first of a series of posts to support my lecture "speech processing with machine learning".
Focus is an introduction to topics related, mainly machine learning as i teach phoneticians which already know a lot about speech.
This page is the landing page which serves as a table of contents for the posts, i will try to introduce a meaningful order for the posts, but sequential read is not required. As said, it's introductory anyway and it's very easy to find much deeper posts on the net. E.g. here's a great list with pictures
Links that are marked with (nkulu) are for posts that use Nkululeko as a hands-on exercise.
Media links
This post is a seminar idea sketch. I try to think up a concept for a seminar and link other blog posts from here if they can help to solve the tasks.
Here's a collection of software recommendations that you might want to install /try before the seminar.
Tasks
Get a recording
- Record a speech of yourself of 3-5 minutes length on a topic that you find emotinally challenging, meaning something you feel strongly about. try to express your feelings while you speak.
- Obviously you might use some other emotional recordings that you collect.
- Convert all into a dedicated audio format, usually 16 kHz sample rate, mono channel, >= 16bit quantization should suffice.
- You might consider storing your data in audformat to be comaptibel with further investigations.
Segment the recording
Perform a segmentation on your recording into parts that have about the right size to carry an emotional expression.
- In a dialog situation a segment would come naturally as it would correspond to the speech segments alternating between the dialog partners (and then would be called a "turn").
- A typical lenght is about 3-7 seconds
- The segmentation can be done manually, via a segmentation tool like Praat, Wavesurfer or even Audacity.
- An alternative approach is to segment the speech automatically, e.g. by a VAD (voice activity detection) algorithm. A quick search delivers e.g. this software based on Praat or the ina spech segmenter
I wrote a new tutorial on how to segment the data using the ina speech segmenter
Annotate the recording
Decide on a target
- Which emotion(s) should be analysed?
- Typically, with emotions, you distinguish between categories (like anger, friendlyness, sadness) and dimensions like pleasure, arousal or dominance (also known as PAD space).
- If you want to compare across participants it's important you have the same concept of what is your target. Typical candidates would be interest, nervousness or valence.
Decide on a scale
- There's a whole standard recommendation on the topic of how to describe emotional states.
- Basically, for this seminar you got to decide if it's binary (0/1, on/off, true/false) or graded, like a discreet value on a Likert scale or simply a continuous value in the range [0, 1] or [-1, 1] (also a surprisingly difficult question)
- Related to that: with respect to Likert scales the most important question is wether there's a neutral value or not.
Do the annotations
- The process of assigning a value to a recording is called annotating, labeling or judging.
- As you decide on a subjective value that depends on your self (temporarily as well as in general) this needs to be done in a real world scenario by as many people as possible (a number between 5 and 20 is quite common).
- How well this works depends on the target and can be computed by the inter-rater-variability, i.e. the degree the labelers agree with each other. Typical measures for this would be Kappa value or Krippendorff's alpha.
- The result of the labeling is a list of the segments with their labels, usually a csv file with as many lines as segments.
- You can do this manually (listen to all segments with your favourite audioplayer and fill the list) or use a tool, e.g. Praat, or (obviously I recommend my own tool) the Speechalyzer, which has been developed to support the annotation of very large datasets.
- An alternative to annotation would be to use a different physical measure that corresponds well with physical arousal as reference, e.g. physical data like blood pressure skin conductivity or respiration rate.
- Of course there's also the possibility to do a continous annotation, i.e disregard segments in favour of a fixed frame size (typically below a second)
Load your data with a data processing environment
- With respect to an environment to run the experiments in, I'd recommend python and jupyter notebooks
- There's a great python module named pandas that you should get familar with. You will learn not only for this seminar, but be able to process any data in a computer for the rest of your existence!
Extract acoustic features
- To perform an acoustic analysis you need to extract some kind of features related to acoustics.
- I distinguish here acoustic from linguistic, i.e. I'd treat transcribed words (and their sentiment) as a different modality.
- I differentiate between three kinds of features:
- expert features meaning manually selected features that should make sense for the target at hand, e.g. kind of everything you would compute with Praat or the about 80 GeMAPS features.
- brute-force features everything you got at hand: usually a combination of frame-based low-level descriptors (one frame: ~ 10-25 msec, a series of values) and statistical functionals, e.g. the 6000+ ComParE16 features. Leave the decision on what is important to an algorithmic approach, e.g. factor analysis.
- learned features Embeddings computed by an ANN encoder (artificial neural net). These features can usually not be interpreted but can be used in machine learning and are an example for representation learning , end-to-end learning and transfer learning, e.g. the TRILL features.
- You can extract/describe features manually (e.g. get speaking time, number of pauses, etc.)
- or use an automated software, for example
Analysis
You might want to collect all data from the seminar participants in a common pandas dataframe to be able to generalize your findings across individual speakers.
- The most obvious question you can try to answer is: is there a correlation between my emotion value (the dependent variable) and the features that I observe?
- Another one would be to look at the effect of independent variables, i.e. other attributes of the speech like speaker, speaker traits (age, sex, dialect), languages.
Statistical measures
- Perform analyses on the most important features for the target
- Compute correlation coefficients for these features
Visualization
- Find good visualizations for correlations
- scatter plots
- box/violin plot per level of target
- cluster plots, clustering the levels of target expressed in color values in a two dimensional feature space (simply use two features or perform a dimensionality reduction algorithm on the features, e.g. a PCA)
Machine learning
- Try automatic prediction of your dependent variable based on the data as test data or split into train and test if you got enough. If you split up the data, be sure not to have the same speakers in train and test set, because otherwise you will only learn some ideosyncratic expression of the speakers.
blog around speech technology