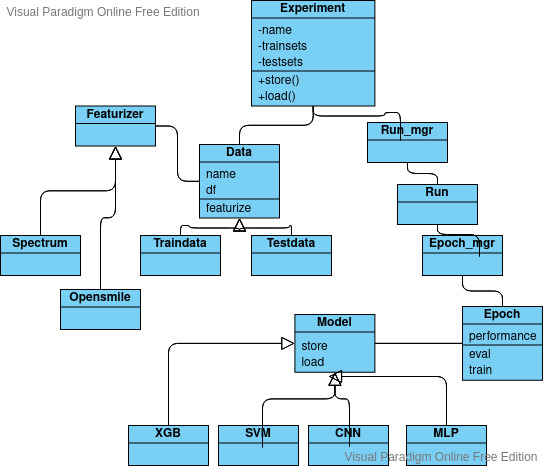
Nkululeko is a framework to build machine learning models that recognize speaker characteristics on a very high level of abstraction (i.e. starting without programming experience).
This post is meant to help you with setting up your first experiment, based on the Berlin Emodb.
1) Set up python
It's written in python so first you have to set up a Python environment
2) Get a database
Load the Berlin emodb database to some location on you harddrive, as discussed in this post. I will refer to the location as "emodb root" from now on.
3) Install nkululeko
Inside your virtual environment, run
pip install nkululekoThis should install nkululeko and all required modules.
It takes a long time and a lot of space, when done intially.
5) Adapt the ini file
Use your favourite editor, e.g. visual studio code and edit the file that defines your experiment. You might start with this demo sample.
You can find more templates to start here and an overview on all the options you can set here
Put the emodb root folder as the emodb value, for me this looks like this
emodb = /home/felix/data/audb/emodbAn overview on all nkululeko options should be here
6) Run the experiment
Inside a shell type (or use VSC) and start the process with
python -m nkululeko.nkululeko --config exp_emodb.ini7) Inspect the results
If all goes well, the program should start by extracting opensmile features, and, if you're done, you should be able to inspect the results in the folder named like the experiment: exp_emodb.
There should be a subfolder with a confusion matrix named images` and a subfolder for the textual results named `results
What to do next?
You might be interested in the hello world of nkululeko
.