
Note to install not parselmouth but the package praat-parselmouth:
!pip install praat-parselmouthFirst, some imports
import pandas as pd
import parselmouth
from parselmouth import praat
import opensmile
import audiofileThen, a test file:
testfile = '/home/felix/data/data/audio/testsatz.wav'
signal, sampling_rate = audiofile.read(testfile)
print('length in seconds: {}'.format(len(signal)/sampling_rate))Get the opensmile formant tracks by copying them from the official GeMAPS config file
smile = opensmile.Smile(
feature_set=opensmile.FeatureSet.GeMAPSv01b,
feature_level=opensmile.FeatureLevel.LowLevelDescriptors,
)
result_df = smile.process_file(testfile)
centerformantfreqs = ['F1frequency_sma3nz', 'F2frequency_sma3nz', 'F3frequency_sma3nz']
formant_df = result_df[centerformantfreqs]Get the Praat tracks (smile configuration computes every 10 msec with frame length 20 msec)
sound = parselmouth.Sound(testfile)
formants = praat.call(sound, "To Formant (burg)", 0.01, 4, 5000, 0.02, 50)
f1_list = []
f2_list = []
f3_list = []
for i in range(2, formants.get_number_of_frames()+1):
f1 = formants.get_value_at_time(1, formants.get_time_step()*i)
f2 = formants.get_value_at_time(2, formants.get_time_step()*i)
f3 = formants.get_value_at_time(3, formants.get_time_step()*i)
f1_list.append(f1)
f2_list.append(f2)
f3_list.append(f3)To be sure: compare the size of the output:
print('{}, {}'.format(result_df.shape[0], len(f1_list)))combine and inspect the result:
formant_df['F1_praat'] = f1_list
formant_df['F2_praat'] = f2_list
formant_df['F3_praat'] = f3_list
formant_df.head()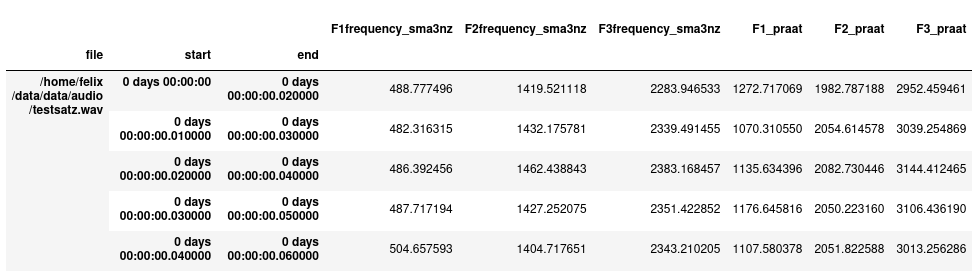
Thank you for this useful tutorial.
I checked a few vowels and I got surprised by how much the results by OpenSmile are unreliable (at least compared to Praat).
yes, that’s mainly due to the missing smoothing i guess
Can you point me to a good tutorial on the smoothing approaches that will make OpenSmile perform closer to Praat? What feature sets might produce better results as opposed to GeMAPSv01b?
Thanks!
Sorry, i don’t think there are any tutorials to smoothing approaches for opensmile LLDs.
Wrt second question: embeddings from transformer pre-trained networks like e.g. wav2vec2 usually work much better, when dealing with speech data