
i recorded a screencast on how to install java, git and emofilt on Windows 10.
Monthly Archives: March 2021
screencast zum Einrichten von python / jupyer notebook unter windows 10
Ich habe gerade ein neues Screencast aufgenommen um zu demonstrieren wie python und jupyter notebook unter Windows 10 installiert werden kann:
Feature scaling
Usually machine learning algorithms are not trained with raw data (aka end-to-end) but with features that model the entities of interest.
With respect to speech samples these features might be for example average pitch value over the whole utterance or length of utterance.
Now if the pitch value is given in Hz and the length in seconds, the pitch value will be in the range of [80, 300] and the length, say, in the range of [1.5, 6].
Machine learning approaches now would give higher consideration on the avr. pitch because the values are higher and differ by a larger amount, which is in the most cases not a good idea because it's a totally different feature.
A solution to this problem is to scale all values so that the features have a mean of 0 and standard deviation of 1.
This can be easily done with the preprocessing API from sklearn:
from sklearn import preprocessing
scaler = StandardScaler()
scaled_features = preprocessing.scaler.fit_transform(features)Be aware that the use of the standard scaler only makes sense if the data follows a normal distribution.
Recording and transcribing a speech sample on Google colab“
Set up the recording method using java script:
# all imports
from IPython.display import Javascript
from google.colab import output
from base64 import b64decode
RECORD = """
const sleep = time => new Promise(resolve => setTimeout(resolve, time))
const b2text = blob => new Promise(resolve => {
const reader = new FileReader()
reader.onloadend = e => resolve(e.srcElement.result)
reader.readAsDataURL(blob)
})
var record = time => new Promise(async resolve => {
stream = await navigator.mediaDevices.getUserMedia({ audio: true })
recorder = new MediaRecorder(stream)
chunks = []
recorder.ondataavailable = e => chunks.push(e.data)
recorder.start()
await sleep(time)
recorder.onstop = async ()=>{
blob = new Blob(chunks)
text = await b2text(blob)
resolve(text)
}
recorder.stop()
})
"""
def record(fn, sec):
display(Javascript(RECORD))
s = output.eval_js('record(%d)' % (sec*1000))
b = b64decode(s.split(',')[1])
with open(fn,'wb') as f:
f.write(b)
return fnRecord something:
filename = 'felixtest.wav'
record(filename, 5)Play it back:
import IPython
IPython.display.Audio(filename)install Google speechbrain
%%capture
!pip install speechbrain
import speechbrain as sbLoad the ASR nodel train on libri speech:
from speechbrain.pretrained import EncoderDecoderASR
asr_model = EncoderDecoderASR.from_hparams(source="speechbrain/asr-crdnn-rnnlm-librispeech", savedir="pretrained_model")And get a transcript on your audio:
asr_model.transcribe_file(audio_file )Record sound from microphone
This works if you got "PortAudio" on your system.
import audiofile as af
import sounddevice as sd
def record_audio(filename, seconds):
fs = 16000
print("recording {} ({}s) ...".format(filename, seconds))
y = sd.rec(int(seconds * fs), samplerate=fs, channels=1)
sd.wait()
y = y.T
af.write(filename, y, fs)
print(" ... saved to {}".format(filename))Use speechalyzer to walk through a large set of audio files
I wrote speechalyzer in Java to process a large set of audio files. Here's how you could use this on your audio set.
Install and configure
1) Get it and put it somewhere on your file system, don't forget to also install its GUI, the Labeltool
2) Make sure you got Java on your system.
3) Configure both programs by editing the resource files.
Run
The easiest case is if all of your files are in one directory. You would simply start the Speechalyzer like so (you need to be in the same directory):
java - jar Speechalyzer.jar -rd <path to folder with audio files> &make sure you configured the right audio extension and sampling rate in the config file (wav format, 16kHz is default).
Then change to the Labeltool directory and start it simply like this:
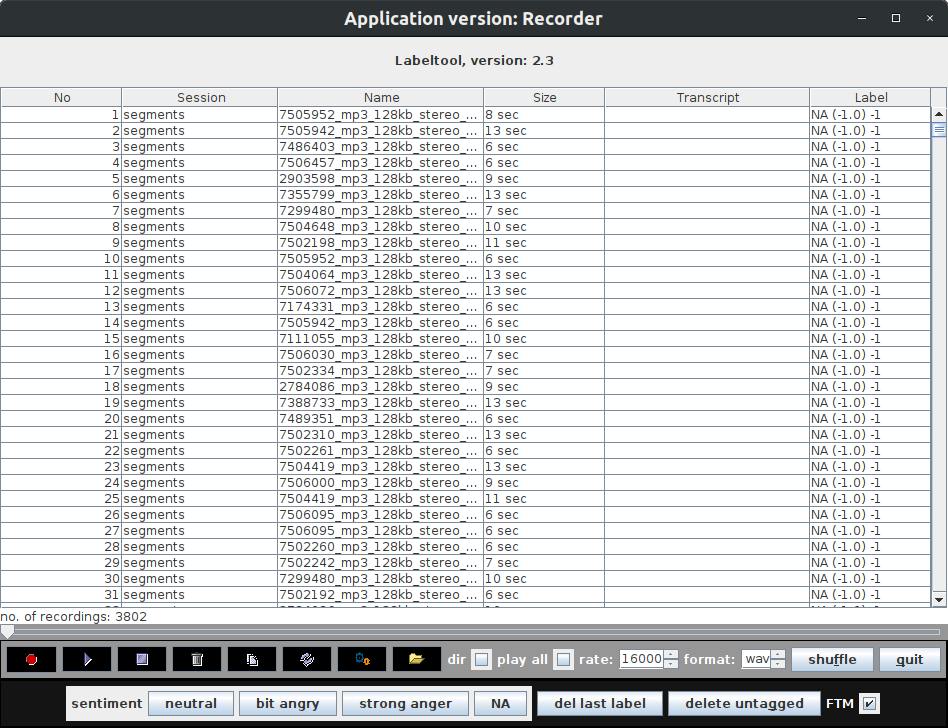
java - jar Labeltool.jar &again you might have to adapt the sample rate in the config file (or set it in the GUI). Note you need to be inside the Labeltool directory. Here is a screenshot of the Labeltool displaying some files which can be annotated, labeled or simply played in a chain:
How to compare formant tracks extracted with opensmile vs. Praat
Note to install not parselmouth but the package praat-parselmouth:
!pip install praat-parselmouthFirst, some imports
import pandas as pd
import parselmouth
from parselmouth import praat
import opensmile
import audiofileThen, a test file:
testfile = '/home/felix/data/data/audio/testsatz.wav'
signal, sampling_rate = audiofile.read(testfile)
print('length in seconds: {}'.format(len(signal)/sampling_rate))Get the opensmile formant tracks by copying them from the official GeMAPS config file
smile = opensmile.Smile(
feature_set=opensmile.FeatureSet.GeMAPSv01b,
feature_level=opensmile.FeatureLevel.LowLevelDescriptors,
)
result_df = smile.process_file(testfile)
centerformantfreqs = ['F1frequency_sma3nz', 'F2frequency_sma3nz', 'F3frequency_sma3nz']
formant_df = result_df[centerformantfreqs]Get the Praat tracks (smile configuration computes every 10 msec with frame length 20 msec)
sound = parselmouth.Sound(testfile)
formants = praat.call(sound, "To Formant (burg)", 0.01, 4, 5000, 0.02, 50)
f1_list = []
f2_list = []
f3_list = []
for i in range(2, formants.get_number_of_frames()+1):
f1 = formants.get_value_at_time(1, formants.get_time_step()*i)
f2 = formants.get_value_at_time(2, formants.get_time_step()*i)
f3 = formants.get_value_at_time(3, formants.get_time_step()*i)
f1_list.append(f1)
f2_list.append(f2)
f3_list.append(f3)To be sure: compare the size of the output:
print('{}, {}'.format(result_df.shape[0], len(f1_list)))combine and inspect the result:
formant_df['F1_praat'] = f1_list
formant_df['F2_praat'] = f2_list
formant_df['F3_praat'] = f3_list
formant_df.head()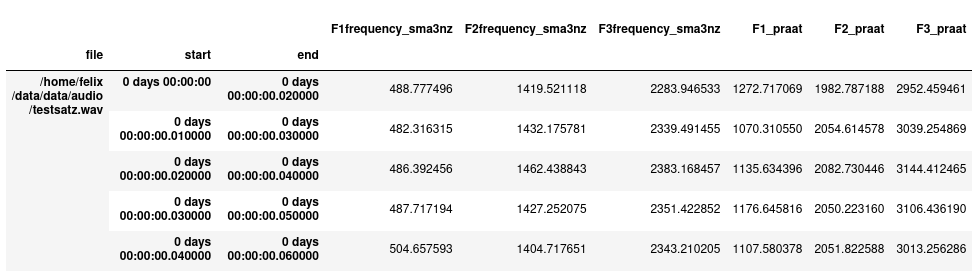
How to extract formant tracks with Praat and python
This tutorial was adapted based on the examples from David R Feinberg
This tutorial assumes you started a Jupyter notebook . If you don't know what this is, here's a tutorial on how to set one up (first part)
First you should install the parselmouth package, which interfaces Praat with python:
!pip install -U praat-parselmouthwhich you would then import:
import parselmouth
from parselmouth import praatYou do need some audio input (wav header, 16 kHz sample rate)
testfile = '/home/felix/data/data/audio/testsatz.wav'And would then read in the sound with parselmouth like this:
sound = parselmouth.Sound(testfile) Here's the code to extract the first three formant tracks, I guess it's more or less self-explanatory if you know Praat.
First, compute the occurrences of periodic instances in the signal:
f0min=75
f0max=300
pointProcess = praat.call(sound, "To PointProcess (periodic, cc)", f0min, f0max)then, compute the formants:
formants = praat.call(sound, "To Formant (burg)", 0.0025, 5, 5000, 0.025, 50)And finally assign formant values with times where they make sense (periodic instances)
numPoints = praat.call(pointProcess, "Get number of points")
f1_list = []
f2_list = []
f3_list = []
for point in range(0, numPoints):
point += 1
t = praat.call(pointProcess, "Get time from index", point)
f1 = praat.call(formants, "Get value at time", 1, t, 'Hertz', 'Linear')
f2 = praat.call(formants, "Get value at time", 2, t, 'Hertz', 'Linear')
f3 = praat.call(formants, "Get value at time", 3, t, 'Hertz', 'Linear')
f1_list.append(f1)
f2_list.append(f2)
f3_list.append(f3)How to synthesize a text to speech with Google speech API
This tutorial assumes you started a Jupyter notebook . If you don't know what this is, here's a tutorial on how to set one up (first part)
There is a library for this that's based on the Google translation service that still seems to work: gtts.
You would start by installing the packages used in this tutorial:
!pip install -U gtts pygame python-vlcThe you can import the package:
from gtts import gTTS, define a text and a configuration:
text = 'Das ist jetzt mal was ich so sage, ich finde das Klasse!'
tts = gTTS(text, lang='de')and synthesize to a file on disk:
audio_file = './hello.mp3'
tts.save(audio_file)which you could then play back with vlc
from pygame import mixer
import vlc
p = vlc.MediaPlayer(audio_file)
p.play()How to get my speech recognized with Google ASR and python
What you need to do this at first is to get yourselg a Google API key,
- you need to register with Google speech APIs, i.e. get a Google cloud platform account
- you need to share payment details, but (at the time of writing, i think) the first 60 minutes of processed speech per month are free.
I export my API key each time I want to use this like so:
export GOOGLE_APPLICATION_CREDENTIALS="/home/felix/data/research/Google/api_key.json"This tutorial assumes you did that and you started a Jupyter notebook . If you don't know what this is, here's a tutorial on how to set one up (first part)
Bevor you can import the Google speech api make shure it's installed:
!pip install google-cloud
!pip install --upgrade google-cloud-speechThen you would import the Google Cloud client library
from google.cloud import speech
import ioInstantiate a client
client = speech.SpeechClient()And load yourself a recorded speech file, should be wav format 16kHz sample rate
speech_file = '/home/felix/tmp/google_speech_api_test.wav'if you run into problems recording one: here is the code that worked for me:
import sounddevice as sd
import numpy as np
from scipy.io.wavfile import write
sr = 16000 # Sample rate
seconds = 3 # Duration of recording
data = sd.rec(int(seconds * fs), samplerate=sr, channels=1)
sd.wait() # Wait until recording is finished
# Convert `data` to 16 bit integers:
y = (np.iinfo(np.int16).max * (data/np.abs(data).max())).astype(np.int16)
wavfile.write(speech_file fs, y)then get yourself an audio object
with io.open(speech_file, "rb") as audio_file:
content = audio_file.read()
audio = speech.RecognitionAudio(content = content)Configure the ASR
config = speech.RecognitionConfig(
encoding=speech.RecognitionConfig.AudioEncoding.LINEAR16,
sample_rate_hertz=16000,
language_code="de-DE",
)Detects speech in the audio file
response = client.recognize(config=config, audio=audio)and show what you got (with my trial only the first alternative was filled):
for result in response.results:
for index, alternative in enumerate(result.alternatives):
print("Transcript {}: {}".format(index, alternative.transcript))