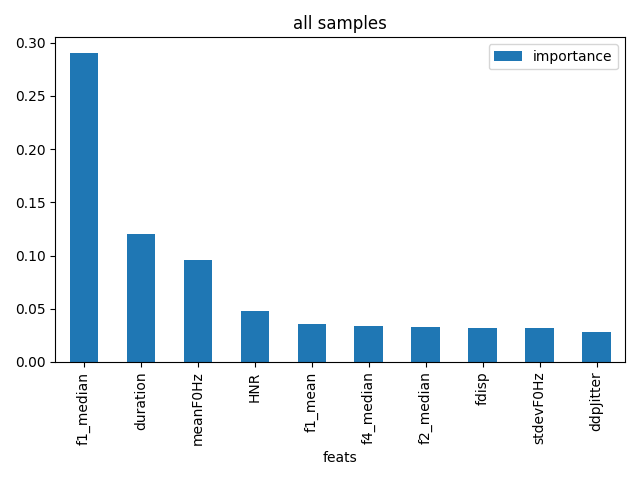
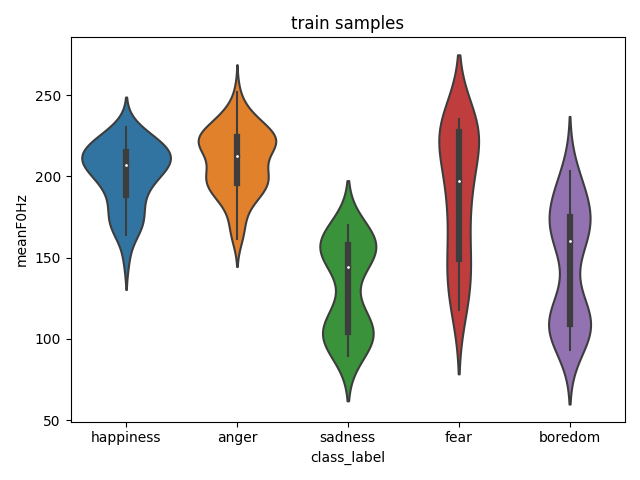
Usually in machine learning, you train your predictor on a train set, tune meta-parameters on a dev (development or validation set ) and evaluate on a test set.
With nkululeko, there currently the test set is not, as there are only two sets that can be specified: train and evaluation set.
A work-around is to use the test module to evaluate your best model on a hold out test set at the end of your experiments.
All you need to do is to specify the name of the test data in your [DATA] section, like so (let's call it myconf.ini):
[EXP]
save = True
....
[DATA]
databases = ['my_train-dev_data']
...
tests = ['my_test_data']
my_test_data = ./data/my_test_data/
my_test_data.split_strategy = test
...you can run the experiment module with your config:
python -m nkululeko.nkululeko --config myconf.iniand then, after optimization (of predictors, features sets and meta-parameters), use the test module
python -m nkululeko.test --config myconf.iniThe results will appear at the same place as all other results, but the files are named with test and the test database as a suffix.
If you need to compare several predictors and feature sets, you can use the nkuluflag module
All you need to do, is, in your main script, if you call the nkuluflag module, pass a parameter (named --mod) to tell it to use the test module:
cmd = 'python -m nkululeko.nkuluflag --config myconf.ini --mod test '