
This post gives an overview on popular machine learners in a nutshell.
Lots of site on the internet give great detail on this and you should take a few minuted to check them out.
Table of Contents
Preliminaries and some naming conventions
In general, all these approaches work by extracting features from data and comparing a test sample's features with the features derived from a training set to predict some class or value in case of regression.
So they work with two phases:
- During training, the parameters of the approach are learned, thereby creating the model.
- A test time, unknown test samples get predicted by the model.
In addition, most of these approaches can be customized by meta-parameters which also can be learned by some meta algorithm, but not during a normal training.
One thing all of these approaches have in common is that they model the world by "densing" down the real values, i.e. the data, to a simpler form at some time (feature extraction), so they all can be seen as some kind of dimensionality reduction
On the one hand you lose information this way, on the other this is not a problem because you usually are interested in some kind of underlying principle that generated your training data, and not so much in the training data itself.
Still you got a trade-off between generality and specificity
Obviously, the following list is by far not complete, I simply selected the ones that were most commonly used during my professional life.
Linear regression
To represent the dependency of a dependend and an independend variable by a straight line. The price question is how to learn the two parameters of the line (a and b of y=ax+b) using the training data. One approach would be gradient descent with a Perceptron.
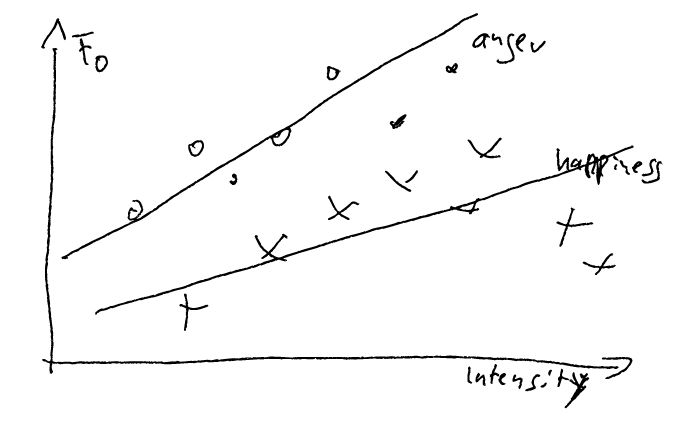
Fig.: Two linear regression models for anger and happiness based on mean fundamental frequency (F0)
GMMs
A Gaussian is a way to describe a distribution with two values: mean and variance. Now one way to distinguish two kinds of things is two distinguish them by the distributions of their features, e.g. herrings from trouts by the size of their fins.
Gaussian mixture models model one distribution of each feature by a mix of several Gaussians, hence their name.
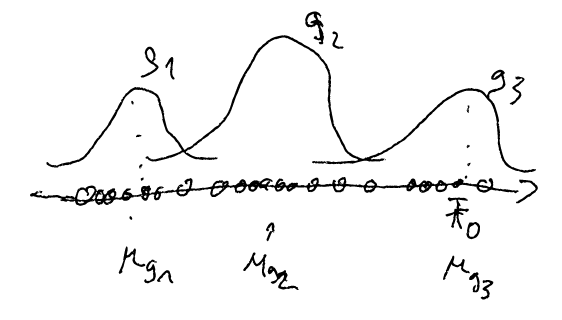
Fig.: A Gaussian mixture model for one feature (mean F0) represented by three Gaussians
(Naive) Bayes
Bayes statistics is fundamentally different from so-called frequentist statistics, as it takes prior knowledge of the problem into account.
The Bayesian formula tells us how likely an event (the class we want to distinguish) can happen in conjunction with another event (the feature that we observe).
During training the Bayes classifier updates its believe about the world, using absolute or estimated frequencies as prior knowledge.
The approach is called naive because it assumes that each input feature is independent, which is most of the time not true.
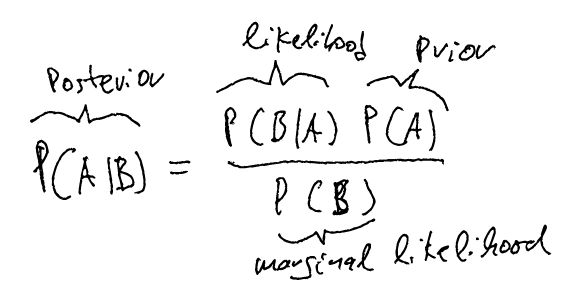
Fig.: Bayes formular predicts the occurence of some event A, given B by the co-occurence of B, given A (learned), normalized by the independent probabilities of A and B.
KNN (k nearest neighbor)
K nearest neighbor is an approach to assign test data, given its k (given parameter) nearest neighbors (in the feature space, by some distance metrics) either the most common class or some property value as an average.
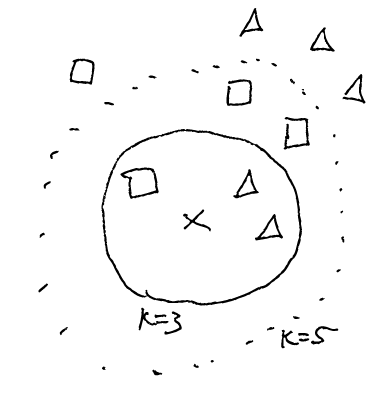
Fig.: Different results for x if k=3 or k=5
Support vector machines
Support vector machines are algorithms motivated by vector geometry
They construct hyperplanes in N-dimensional (number of features) space by maximizing the margin between data points from different classes.
The function that defines the hyperplane is called the kernel function and can be parameterized.
They can be combined with GMMS if the data is approximated by them.

Fig.: A two-dimensional hyper-plane separates two classes, defined by support vectors.
CART (classification and regression trees)
Perhaps the most straightforward way to categorize data: order its parameters in a tree like fashion with the features as twigs and the data points as leaves.
The tree is learned from the training set (and can be probabilistic).
The big advantage of this model is that it is easily interpretable to humans.

Fig.: A tree predicts an emotion category for some input based on mean F0, speech rate (SR) and Harmonic-to-noise ratio (HNR)
XGBoost
A sophisticated algorithm loosely based on CARTS as it combines Random Forests (ensembles of trees) with boosting more successful ones.
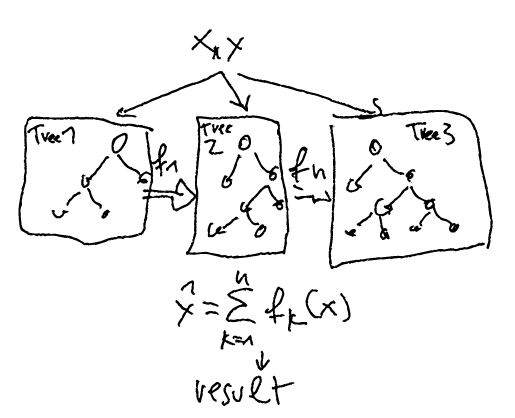
Fig.: XG boost as a result of trees, weighted by functions.
MLP (Multi-layer perceptron)
As the name suggests, these algorithms are derived from the original Perceptron idea that is inspired by the human brain.
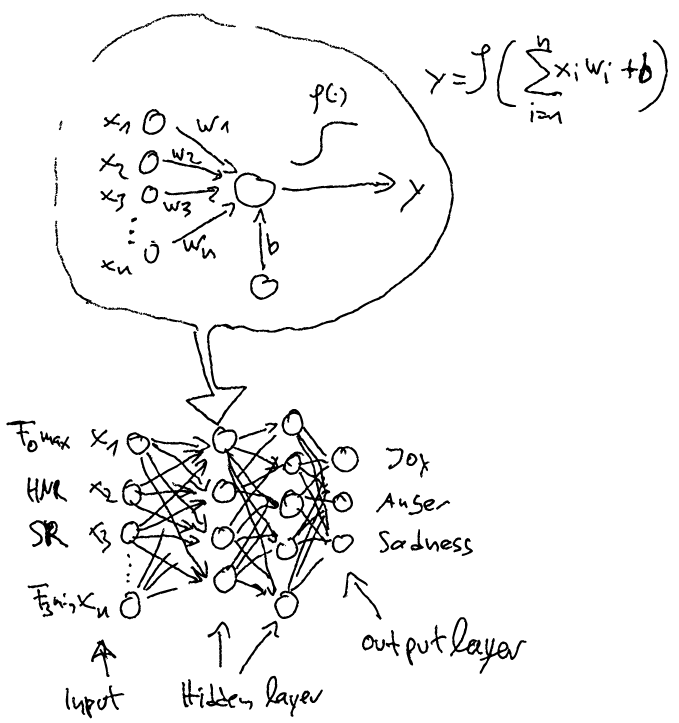
Fig.: A feed forward network consisting of layers of Perceptrons, again predicting basic emotions for some input based on utterance global acoustic values.
Deep learning
Concepts for deep learning are discussed here