The speech AI company audEERING open sourced a model to classify emotional dimensions, i.e. arousal, valence and dominance.
In this tutorial, let's see how the open-domain emotional database EmoDB is categorized by this model (which is trained on a different emotional database: MSPPodcast).
Thanks to Johannes Wagner for providing the code used in this tutorial.
We'll do this in a jupyter notebook.
Here is the list of requirements you need to install (after having activated your environment):
pip install juypter pandas umap-learn audb audonnx matplotlib seaborn audinterfaceWe start our notebook with the imports:
import numpy as np
import pandas as pd
import umap
import matplotlib.pyplot as plt
import seaborn as sns
import audeer
import audonnx
import audb
import audformat
import audinterface
# and two constants:
sampling_rate = 16000
model_id = '6bc4a7fd-1.1.0'We'll then load the model like this:
url = f'https://zenodo.org/record/6221127/files/w2v2-L-robust-12.{model_id}.zip'
cache_root = audeer.mkdir('cache')
model_root = audeer.mkdir('model')
archive_path = audeer.download_url(url, cache_root, verbose=True)
audeer.extract_archive(archive_path, model_root)
model = audonnx.load(model_root)
# and inspect it:
print(model)We load the database:
db = audb.load(
'emodb',
version='1.3.0',
format='wav',
mixdown=True,
sampling_rate=sampling_rate,
)
emotion_test = db[f'emotion.categories.test.gold_standard']['emotion'].get()
emotion_train = db[f'emotion.categories.train.gold_standard']['emotion'].get()
emotion = pd.concat([emotion_test, emotion_train])
speaker = db['files']['speaker'].get(emotion.index)
gender = db['files']['speaker'].get(emotion.index, map='gender')
transcription = db['files']['transcription'].get(emotion.index)
df_labels = audformat.utils.concat([emotion, speaker, gender, transcription])
df_labels.head(1)
print(df_labels.shape)We create two interface: one for the logits (emotional dimensions) and one for the features (embeddings: pen-ultimate layer of network).
interface_logits = audinterface.Feature(
model.labels('logits'), # feature names
process_func=model,
process_func_args={
'outputs': 'logits', # output 'logits'
},
verbose=True,
)
interface_features = audinterface.Feature(
model.labels('hidden_states'),
process_func=model,
process_func_args={
'outputs': 'hidden_states',
},
verbose=True,
)and then we can extract them simply by stating:
df_features = interface_features.process_index(
df_labels.index,
cache_root=audeer.path(cache_root, model_id, 'features'),
)
df_logits = interface_logits.process_index(
df_labels.index,
cache_root=audeer.path(cache_root, model_id, 'logits'),
)
# and inspect them
print(df_logits.head(1))
print(df_logits.shape, df_features.shape)To visualize, we transform the features to two dimensions:
y_umap = umap.UMAP(
n_neighbors=10,
random_state=0,
).fit_transform(df_features.values)
pd.DataFrame(
y_umap,
df_features.index,
columns=['umap-0', 'umap-1'],
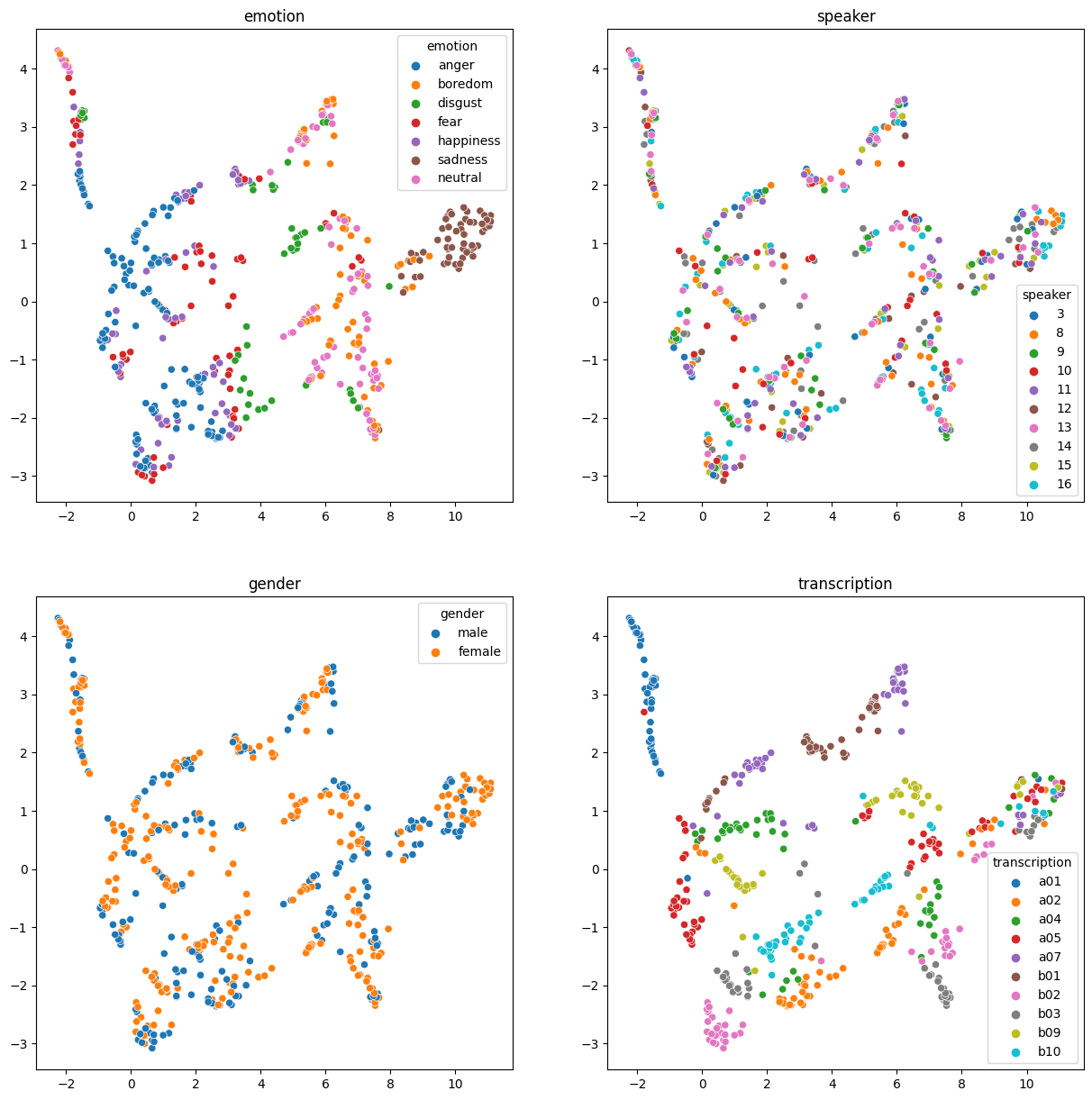
)And then plot these, colored by the labels of the database:
fig, axs = plt.subplots(2, 2, figsize=[15, 15])
axs = axs.flatten()
for ax, column in zip(axs, df_labels):
ax.set_title(column)
_ = sns.scatterplot(
x=y_umap[:, 0],
y=y_umap[:, 1],
hue=df_labels[column],
ax=ax,
)Which should leave you with: