This is one of a series of posts about how to use nkululeko.
Although Nkululeko is meant as a programming library, many experiments can be done simply by adapting the configuration file of the experiment. If you're unfamilar with nkululelo, you might want to start here.
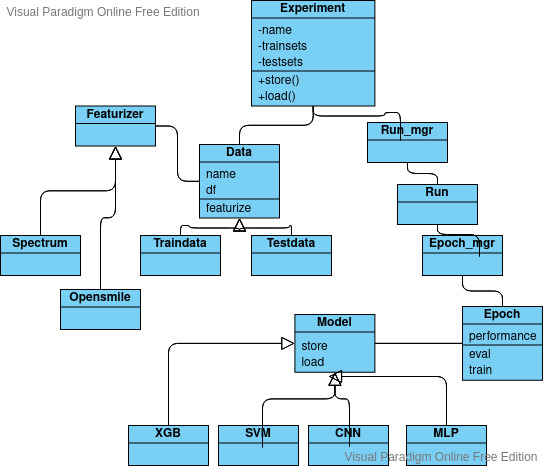
This post is about maschine classification (as opposed to regression problems) and an introduction how to combine different features sets with different classifiers.
In this post I will only talk about the config file, the python file can be re-used.
I'll walk you through the sections of the config file (all options here):
The first section deals with general setup:
[EXP]
# root is the base directory for the experiment relative to the python call
root = ./experiment_1/
# mainly a name for the top folder to store results (inside root)
name = exp_A
# needed only for neural net classifiers
#epochs = 100
# needed only for classifiers with random initialization
# runs = 3
The DATA section deals with the data sets:
[DATA]
# list all the databases you will be using
databases = ['emodb']
# state the path to the audformat root folder
emodb = /home/felix/data/audb/emodb
# split train and test based on different random speakers
emodb.split_strategy = speaker_split
# state the percentage of test speakers (in this case 4 speakers, as emodb only has 10 speakers)
emodb.testsplit = 40
# for a subsequent run you might want to skip the speaker selection as it requires to extract features for each run
# emodb.split_strategy = reuse # uncomment the other strategy then
# the target label that should be classified
target = emotion
# the categories for this label
labels = ['anger', 'boredom', 'disgust', 'fear', 'happiness', 'neutral', 'sadness']
The next secton deals with the features that should be used by the classifier.
[FEATS]
# the type of features to use
type = ['os']
The following altenatives are currently implemented (only os and trill are opensource):
- type = os # opensmile features
- type = mld # mid level descriptors, to be published
- type = trill # TRILL features requires keras to be installed
- type = spectra # log mel spectra, for convolutional ANNs
Next comes the MODEL section which deals with the classifier:
[MODEL]
# the main thing to sepecify is the kind of classifier:
type = xgb
Choices are:
- type = xgb # XG-boost algorithm, based on classification trees
- type = svm # Support Vector Machines, a classifier based on decision planes
- type = mlp # Multi-Layer-Perceptron, needs a layer-layout to be specified, e.g. layers = {'l1':64}
And finally, the PLOT section specifies possible additional visualizations (a confusion matrix is always plotted)
[PLOT]
tsne = True
A t-SNE plot can be useful to estimate if the selected features seperate the categories at all.