
There is a framework called OpenSMILE published on Github that can be used to extract high level acoustic features from audio signals and I’d like to show you how to use it with Python.
I’ve set up a notebook for this here.
First you need to install opensmile.
pip install opensmileTable of Contents
General procedure
There are two ways to extract a specific acoustic feature with opensmile:
1) Use an existing config that contains your target feature and filter it from the results
2) Write your own config file and extract only your target feature directly
Method 1 is easier but obviously not resource efficient, 2 is better but then to learn the opensmile config syntax and all the existing modules is not trivial.
Using one example for an acoustic feature: formants, we’ll do both ways. The documentation for the python wrapper of opensmile is here
The following assumes you got a test wave file recorded and stored somewhere:
testfp = '/kaggle/input/testdata/testsatz.wav'
IPython.display.Audio(testfp)Method 1): Use an existing config file that includes the first three formant frequencies
We start with instantiating the main extractor class, Smile, with a configuration that includes formants. The GeMAPSv01b features set has been derived from the GeMAPS feature set
smile = opensmile.Smile(
feature_set=opensmile.FeatureSet.GeMAPSv01b,
feature_level=opensmile.FeatureLevel.LowLevelDescriptors,
)Extract this for our test sentence, out comes a pandas dataframe
result_df = smile.process_file(testfp)
print(result_df.shape)Now use only the three center formant frequencies
centerformantfreqs = [‘F1frequency_sma3nz’, ‘F2frequency_sma3nz’, ‘F3frequency_sma3nz’]
formant_df = result_df[centerformantfreqs]
formant_df.head()This should be your ouput: per frame three values: the center frequencies of the formants:
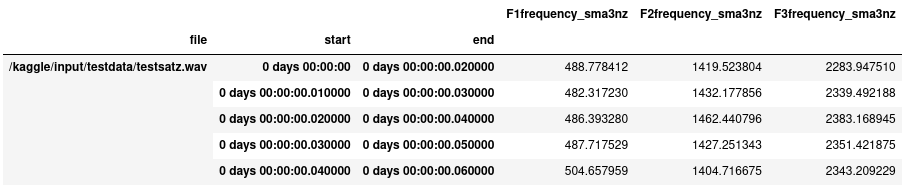 .
.
Method 2): Write your own config file
The documentation for opensmile config files is here.
Most often it is probably easier to look at an existing config file and copy/paste the components you need.
You could edit the opensmile config in a string:
formant_conf_str = '''
[componentInstances:cComponentManager]
instance[dataMemory].type=cDataMemory
;;; default source
[componentInstances:cComponentManager]
instance[dataMemory].type=cDataMemory
;;; source
\{\cm[source{?}:include external source]}
;;; main section
[componentInstances:cComponentManager]
instance[framer].type = cFramer
instance[win].type = cWindower
instance[fft].type = cTransformFFT
instance[resamp].type = cSpecResample
instance[lpc].type = cLpc
instance[formant].type = cFormantLpc
[framer:cFramer]
reader.dmLevel = wave
writer.dmLevel = frames
copyInputName = 1
frameMode = fixed
frameSize = 0.025000
frameStep = 0.010000
frameCenterSpecial = left
noPostEOIprocessing = 1
[win:cWindower]
reader.dmLevel=frames
writer.dmLevel=win
winFunc=gauss
gain=1.0
[fft:cTransformFFT]
reader.dmLevel=win
writer.dmLevel=fft
[resamp:cSpecResample]
reader.dmLevel=fft
writer.dmLevel=outpR
targetFs = 11000
[lpc:cLpc]
reader.dmLevel=outpR
writer.dmLevel=lpc
p=11
method=acf
lpGain=1
saveLPCoeff=1
residual=0
forwardFilter=0
lpSpectrum=0
lpSpecBins=128
[formant:cFormantLpc]
reader.dmLevel=lpc
writer.dmLevel=formant
saveIntensity=1
saveBandwidths=0
maxF=5500.0
minF=50.0
nFormants=3
useLpSpec=0
medianFilter=0
octaveCorrection=0
;;; sink
\{\cm[sink{?}:include external sink]}
'''which you can save as a config file:
with open('formant.conf', 'w') as fp:
fp.write(formant_conf_str)Now we reinstantiate our smile object with the custom config
smile = opensmile.Smile(
feature_set=’formant.conf’,
feature_level=’formant’,
)and extract again
formant_df_2 = smile.process_file(testfp)
formant_df_2.head()Voila! The output is should be similar to the one you got with the first method.
Great example!
I am curious if there a reason you did not use cFormantSmoother component in the custom config?
Are there any circumstances when you would prefer to use or not to use the smoother?
E.x I am trying to model vocal tract features using formants. Is smoothing desirable in such situation?
Also I was wondering if frameSize 0.025 is optimal for formants, I have noticed that in GeMAPSv01b wider window is used?
thanks for the comment, i think formantSmoother is exactly what is needed here to add some post sanity checks, I just didn’t have the time yet. For the same reason i didn’t experiment on frameSizes, from my guts i’d say it’d make sense to work with hirarchical levels of window lengths.