
Nkululeko is a tool to ease machine learning on speech databases.
This tutorial should help you to import databases.
There are two formats upported:
1) csv (comma seperated values)
2) audformat
CSV format
The easiest is CSV, you simply create a table with the following informations:
- file: the path to the audio file
- task: is the speaker characteristics value that you want to explore, e.g. age or emotion, or both
and then fill it with values of your database. Optionally, your data can contain any amount of additional information in further columns. Some naming conventions are pre-defined:
- speaker: speaker id, a string being unique for samples from one speaker
- gender: biological sex
- age: an integer between 0 and 100 denoting the age in years.
So a file for emotion might look like this
file, speaker, gender, emotion
<path to>/s12343.wav, s1, female, happy
...You can then specify the data in your initialization file like this:
[DATA]
databases = ['my_db']
my_db.type = csv
my_db = <path to>/my_data_file.csv
my_db.absolute_path = False
...
target = emotionYou should set the flag absolute_path depending on whether
- the file paths start from the location of where you run Nkululeko (or start from root: /), then True
- or they start from the location where the data resides, then False
(if in doubt, just try it out: there should be an error message that the audio files don't exist)
You can not specify split tables with this format, but would have to simply split the file in several databases.
There is an example on how to import the ravdess database here.
And this would be an example ini file to use it:
[EXP]
root = ./tests/results/
name = exp_ravdess
runs = 1
epochs = 1
save = True
[DATA]
databases = ['train', 'test', 'dev']
train = ../nkululeko/data/ravdess/ravdess_train.csv
train.type = csv
train.absolute_path = False
train.split_strategy = train
dev = ../nkululeko/data/ravdess/ravdess_dev.csv
dev.type = csv
dev.absolute_path = False
dev.split_strategy = train
test = ../nkululeko/data/ravdess/ravdess_test.csv
test.type = csv
test.absolute_path = False
test.split_strategy = test
target = emotion
labels = ['angry', 'happy', 'neutral', 'sad']
[FEATS]
type = ['os']
scale = standard
[MODEL]
type = xgbI.e. the splits train and dev get concatenated to a common train set
Fun fact: the result is:
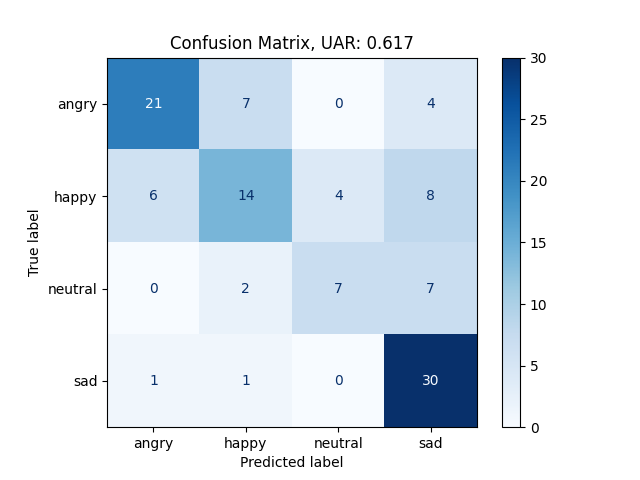
audformat
audformat allows for many usecases, so the specification might be more complex.
So in the easiest case you have a database with two tables, one called files that contains the speaker informations (id and sex) and one called like your task (aka target), so for example age or emotion.
That's the case for our demo example, the Berlin EmoDB, ando so you can include it simply with.
[DATA]
databases = ['emodb']
emodb = /<path to>/emodb/
target = emotion
...But if there are more tables and they have special names, you can specifiy them like this:
[DATA]
databases = ['msp']
# path to data
msp = /<path to>/msppodcast/
# tables with speaker information
msp.files_tables = ['files.test-1', 'files.train']
# tables with task labels
msp.target_tables = ['emotion.test-1', 'emotion.train']
# train and evaluation splits will be provided
msp.split_strategy = specified
# here are the test/evaluatoin split tables
msp.test_tables = ['emotion.test-1']
# here are the training tables
msp.train_tables = ['emotion.train']
target = emotion